L'un de mes grands projets est de me lancer dans le Bug Bounty, mais avant de devenir le Boba Fett du code, je dois apprendre toute la méthodologie du Bug Bounty.

Je vais donc résumer la vidéo "Bug Bounty Hunter Methodology v3" de Jason Haddix (JHaddix) : https://www.youtube.com/watch?v=Qw1nNPiH_Go.
Ressources bibliographiques
Si vous débutez dans le bug hunting, ces ressources sont fortement recommandées :
- The Web Application Hacker's Handbook: Finding and Exploiting Security Flaws
- OWASP Testing Guide v4 (disponible ici)
- Web Hacking 101
- Breaking Into Information Security
- Mastering Modern Web Penetration Testing
Lorsque vous démarrez un nouveau programme de Bug Bounty, une chose essentielle à faire en premier est la reconnaissance de la cible.
Découverte de l'espace IP
Lorsque vous ciblez une organisation, ce que nous voulons faire est d'identifier à la fois ses hôtes mais aussi son espace IP, afin d'avoir une bonne référence de l'ensemble de son système Internet.
Voici quelques ressources qui peuvent être utilisées pour collecter ce type d'informations :
- https://bgp.he.net : la plus courante que les gens utilisent pour trouver le numéro de système autonome d'une organisation (la plage IP qu'ils ont enregistrée)
- https://www.arin.net et https://www.ripe.net : pour trouver les IPs et domaines enregistrés d'une organisation
- https://www.domainiq.com/reverse_whois : vous donne tout ce qui est lié à un nom de domaine via une recherche whois inversée.
- https://www.shodan.io/ : ce site référence les résultats de scans de ports massifs effectués sur Internet. C'est une mine d'or d'informations pour trouver les systèmes Internet d'une organisation.
Découverte de nouvelles cibles (Marques et TLDs)
Il existe certains programmes de Bug Bounty qui ont un scope large. Cela signifie que si vous pouvez identifier que certaines infrastructures appartiennent à cette organisation, ils veulent que vous essayiez de les pirater. Cette section concerne donc la découverte de nouvelles marques et domaines de premier niveau.
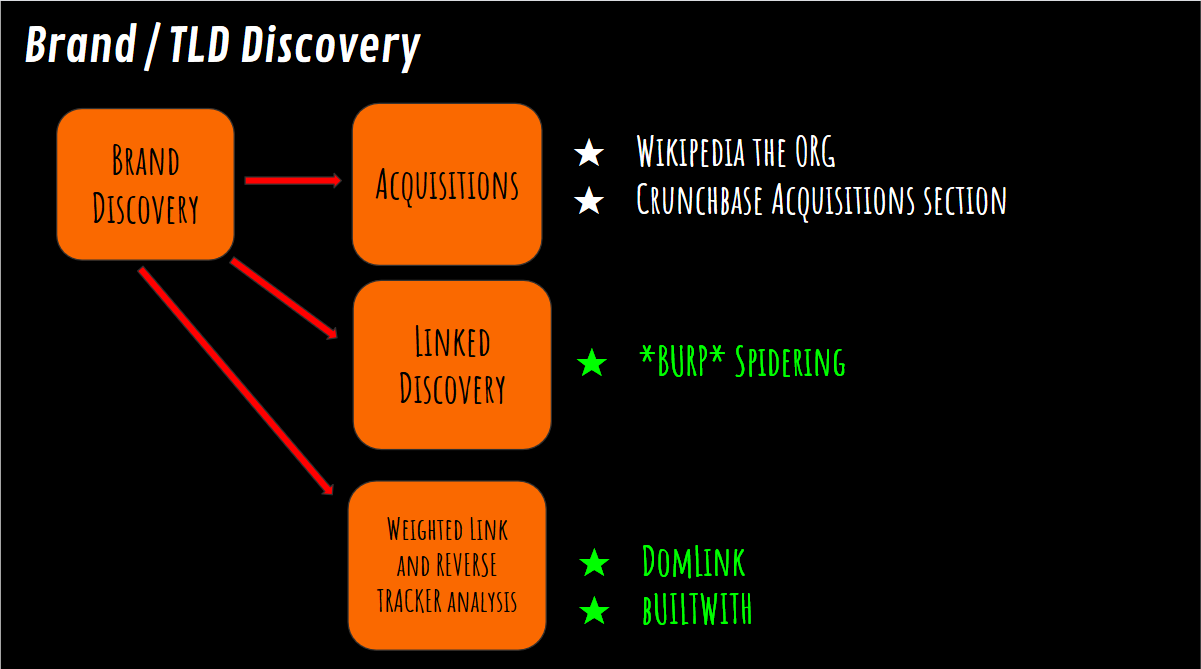
Vous pouvez utiliser Wikipedia et Crunchbase pour rechercher les acquisitions d'entreprises. Quand une entreprise en acquiert une autre, vous voulez immédiatement, en tant que Bounty Hunter, vérifier si cette acquisition est dans le scope. Ces deux sites sont les meilleurs pour surveiller les acquisitions, car les gens utilisent ces deux sites pour trader sur les informations boursières et autres, donc ils restent assez à jour avec les actualités autour de la marque que vous ciblez.
Une autre méthode assez puissante pour découvrir de nouvelles cibles, en utilisant Burp Suite, est une méthode appelée linked discovery :

Le principe de cette méthode est de visiter le site cible lui-même et de voir vers où il redirige. Vous pouvez utiliser cette méthode avec Burp, vous configurez un scope personnalisé (mots-clés) puis vous naviguez sur le site et il va spider tous les hôtes de manière récursive pendant que vous les visitez, et cela va remplir votre arborescence de site dans Burp. Il vous montrera donc tout ce qui correspond aux mots-clés que vous avez définis dans le scope.
Vidéo de démonstration ici : https://youtu.be/Qw1nNPiH_Go?t=879.
La méthode suivante s'appelle DomLink, l'idée avec cette méthode est de regarder de manière récursive le whois inversé de façon programmatique (script python), basé sur qui a enregistré un domaine, puis de créer un lien entre ces domaines.
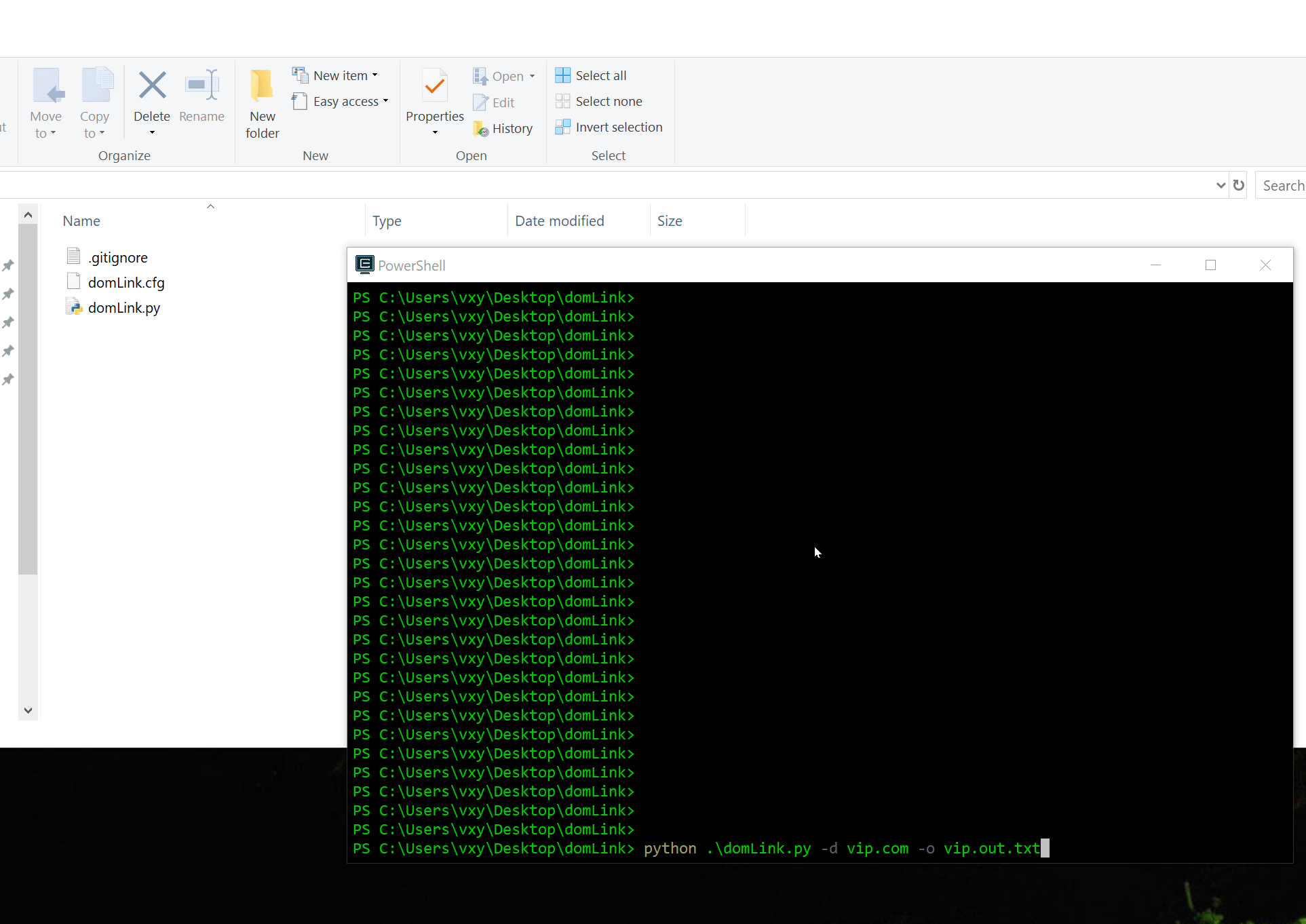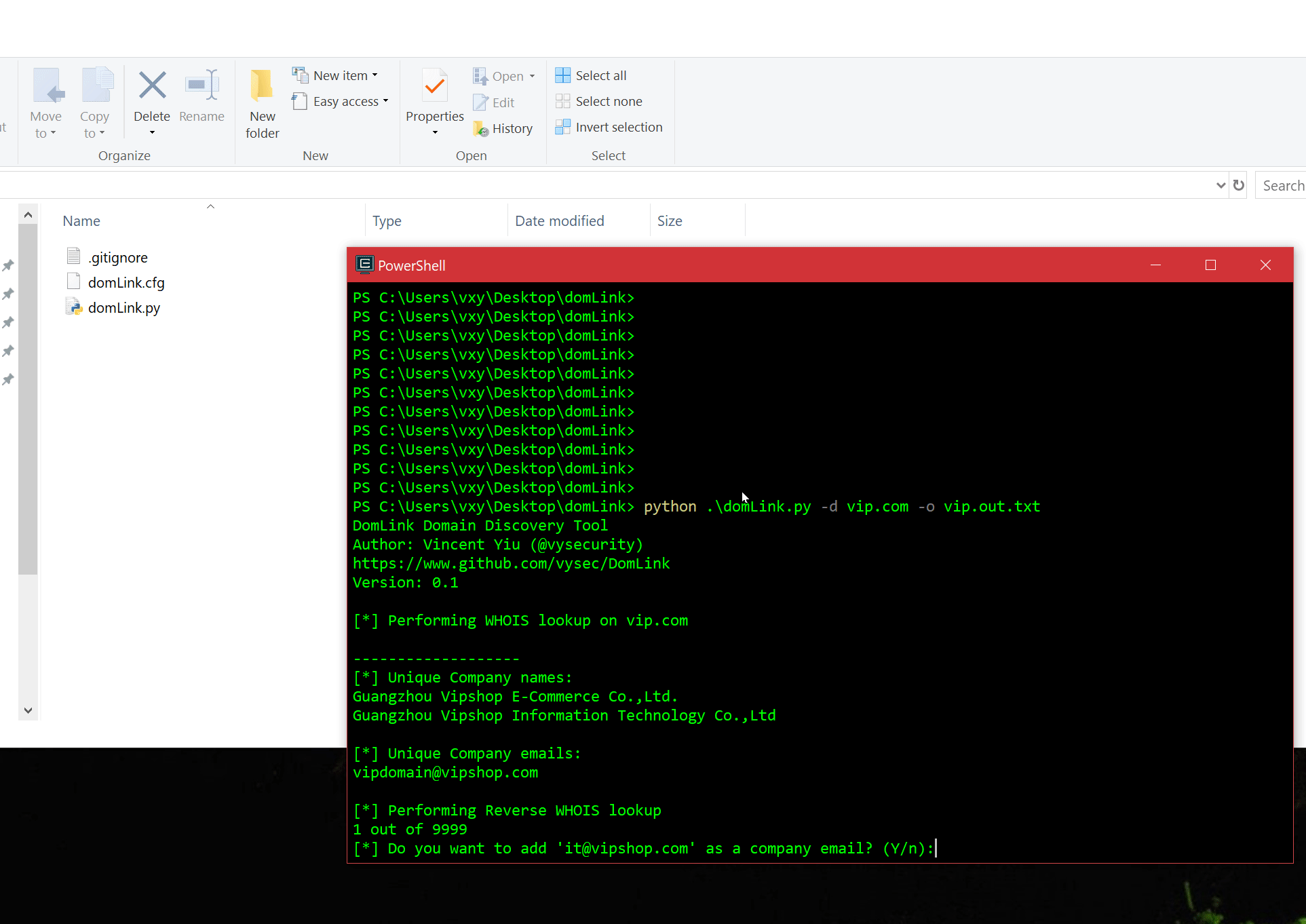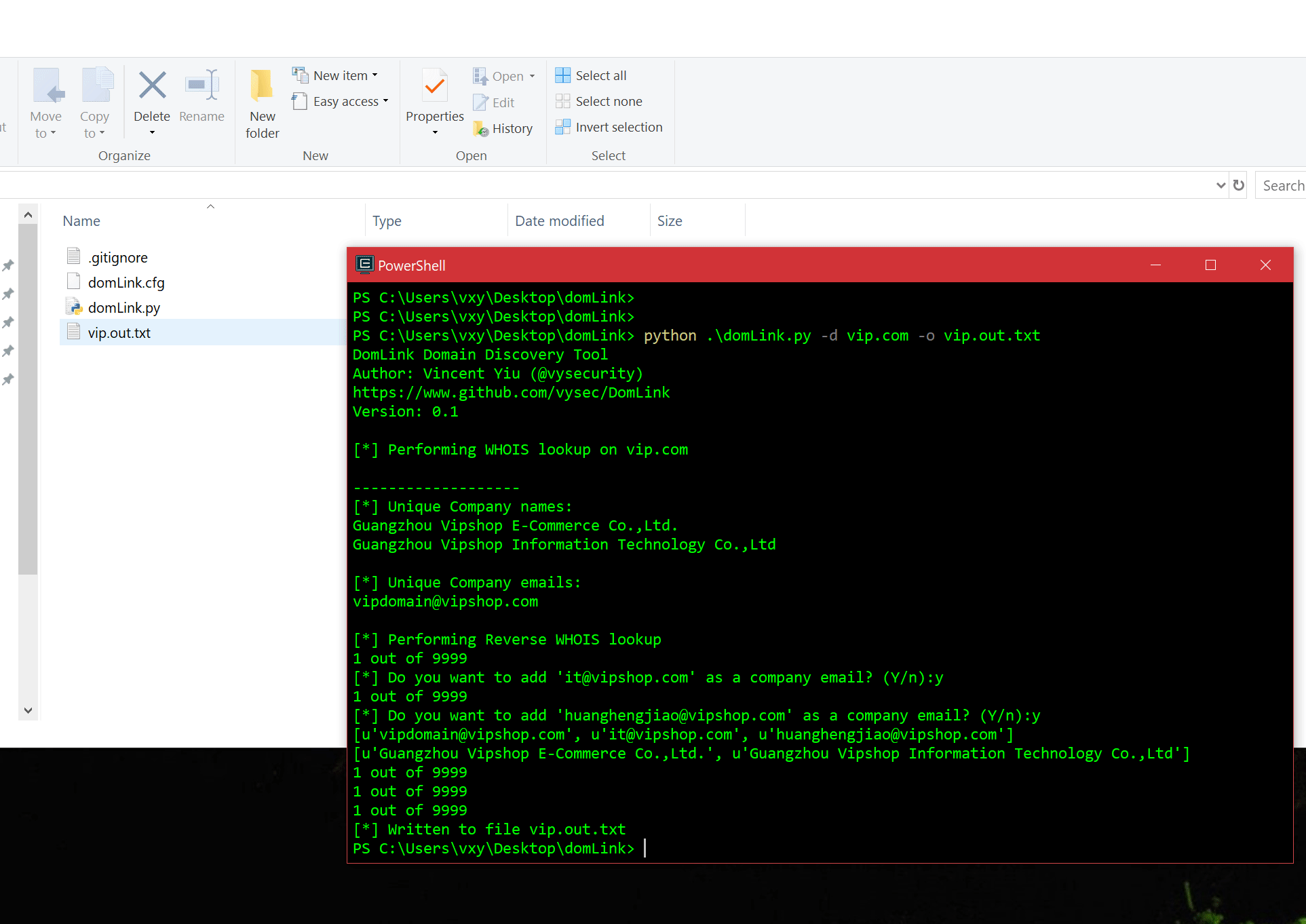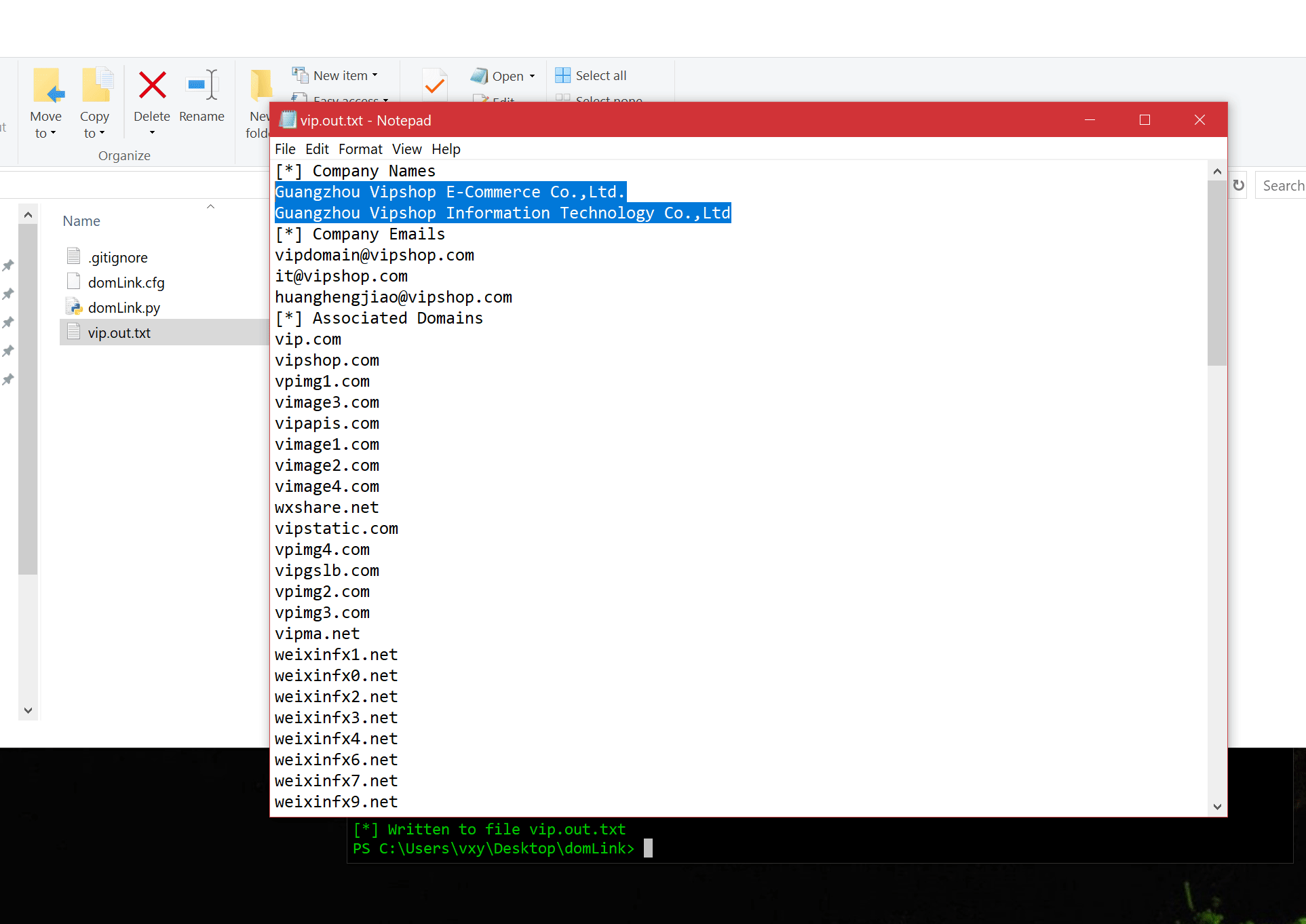
Vous pouvez trouver l'outil DomLink ici : https://github.com/vysecurity/DomLink.
Une autre méthode s'appelle Builtwith, ce site permet de découvrir comment vos sites cibles sont gérés, quelles technologies ils utilisent, les trackers d'analytics qu'ils utilisent, le type de logiciel serveur, tous les frameworks qu'ils utilisent, etc...
Il existe une extension navigateur Builtwith disponible ici, avec quelques fonctionnalités intéressantes. Il y a une fonctionnalité qui permet de lier ensemble la relation d'un site basée sur ses trackers d'analytics, puis elle vous indiquera tous les autres domaines qu'elle a vus dans ses bases de données qui utilisent le même code, vous pouvez donc voir des domaines connexes qui pourraient être liés à votre cible. Cela peut être utile pour trouver des sites qui sont liés à votre cible et dans le scope, mais pas explicitement listés.
Quelques autres méthodes :
- TradeMark dans Google : "TESLA @ 2015", "TESLA @ 2019" INURL:TESLA.COM...
Découverte de nouvelles cibles (Sous-domaines)
Il existe deux façons différentes de trouver des sous-domaines :
- Scrapping de sous-domaines
- Brute forcing de sous-domaines
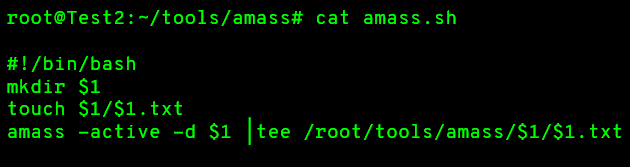
Amass
L'outil Amass dispose de jusqu'à 22 sources qu'il parse, et inclut une tonne de fonctionnalités avancées pour l'énumération de sous-domaines. Vous pouvez trouver l'outil Amass ici : https://github.com/OWASP/Amass.
Cet outil inclut des méthodes de DNS inversé, du scanning par permutation (quand il voit une nomenclature de nommage pour un sous-domaine comme Dev-One, il vérifiera aussi Dev-Two, Dev-Three, etc...).
Vous pouvez utiliser ce script bash pour conserver la sortie de vos exécutions, car Amass n'a pas d'option pour conserver la sortie :
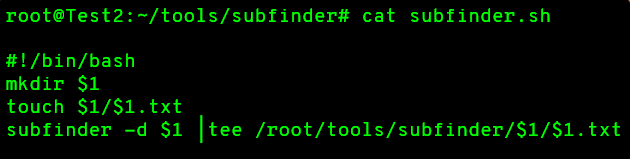
Subfinder
L'outil Subfinder contient la plupart des mêmes sources qu'Amass, avec cet outil vous pouvez obtenir une sortie JSON, et il inclut aussi une section de brute force qui utilise des résolveurs multiples.
Vous pouvez trouver l'outil Subfinder ici : https://github.com/projectdiscovery/subfinder.
Comme pour Amass, vous pouvez utiliser ce script bash pour conserver la sortie de vos exécutions :
MassDNS
MassDNS est un résolveur DNS stub haute performance. MassDNS découpe votre liste à résoudre en petits morceaux et assigne chacun de ces morceaux à un résolveur DNS différent. De plus, il est écrit en C, donc il peut exécuter un dictionnaire d'un million de lignes pour le brute forcing en environ une minute et demie.
Vous pouvez trouver l'outil MassDNS ici : https://github.com/blechschmidt/massdns.
Voici une comparaison entre MassDNS et quelques autres outils de Brute Forcing de sous-domaines :
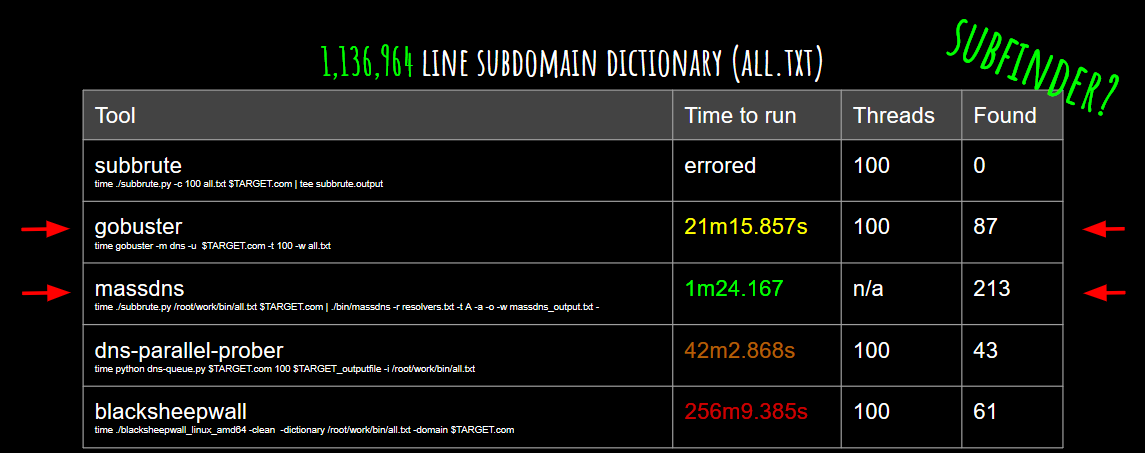
Subfinder utilise la même méthode que MassDNS pour le brute forcing, donc il peut être aussi efficace. Et si vous cherchez un outil sans résolveur multiple, GoBuster est le meilleur pour ce cas.
Donc avec cette méthode de brute forcing de sous-domaines, vous avez besoin d'une bonne liste de sous-domaines à partir de laquelle brute forcer, vous pouvez trouver des listes de sous-domaines ici : https://github.com/jhaddix/SecLists/tree/master/Discovery/DNS.
CommonSpeak et Scans.io
Commonspeak est un outil de génération de wordlist qui exploite les jeux de données publics de la plateforme BigQuery de Google.
Vous pouvez trouver l'outil CommonSpeak ici : https://github.com/pentester-io/commonspeak.
Sur Scans.io vous pouvez trouver le Internet-Wide Scan Data Repository qui est une archive publique de jeux de données de recherche qui décrivent les hôtes et sites sur Internet.
Ces deux outils sont vraiment utiles pour construire de bonnes listes de sous-domaines.
Quelques autres méthodes
Voici quelques autres méthodes pour trouver des sous-domaines :
- Faire du DNSSEC/NSEC/NSEC3 parsing et faire de l'INSEC Walking ou du DNSSEC Walking en utilisant ces utilitaires : LDNSUTILS, NSEC3WALKER, NSEC3MAP
- Reconnaissance Github : chercher des informations sensibles
- Dorking : Clés ADS, Politique de confidentialité, CGU, AWS, S3...
Énumération des cibles
Maintenant que nous avons trouvé des domaines de premier niveau, et peut-être des marques, et que nous avons trouvé tout un tas de sous-domaines de notre cible, il est temps de passer aux sites individuels. La première chose que nous voulons faire est essentiellement du scan de ports.
Quand on parle de scan de ports, le premier outil auquel les gens pensent est NMAP, mais pour tout scan de ports à grande échelle, NMAP prendra une éternité. Donc si vous avez beaucoup d'hôtes, faire un scan de ports complet sur tous prendra une éternité.
MasScan
MasScan est un scanner de ports à l'échelle d'Internet. Il peut scanner l'ensemble d'Internet en moins de 6 minutes, transmettant 10 millions de paquets par seconde, depuis une seule machine.
Voici la commande pour exécuter MasScan :
masscan -p1-65535 -iL $TARGET_LIST --max-rate 100000 -oG $TARGET_OUTPUT
Le paramètre -oG permet de sauvegarder la sortie au format nmap, afin que nous puissions le re-scanner avec le scanning de version de nmap (ça va être utile pour le prochain outil).
Le problème avec MasScan est qu'il n'accepte pas les noms DNS, il n'accepte que les IPs, donc voici un petit script shell pour exécuter un dig sur un domaine, il va aussi retirer un préfixe HTTP ou HTTPS si vous le tirez d'un autre outil, puis exécuter MasScan dessus :

BruteSpray Brute-Force d'identifiants
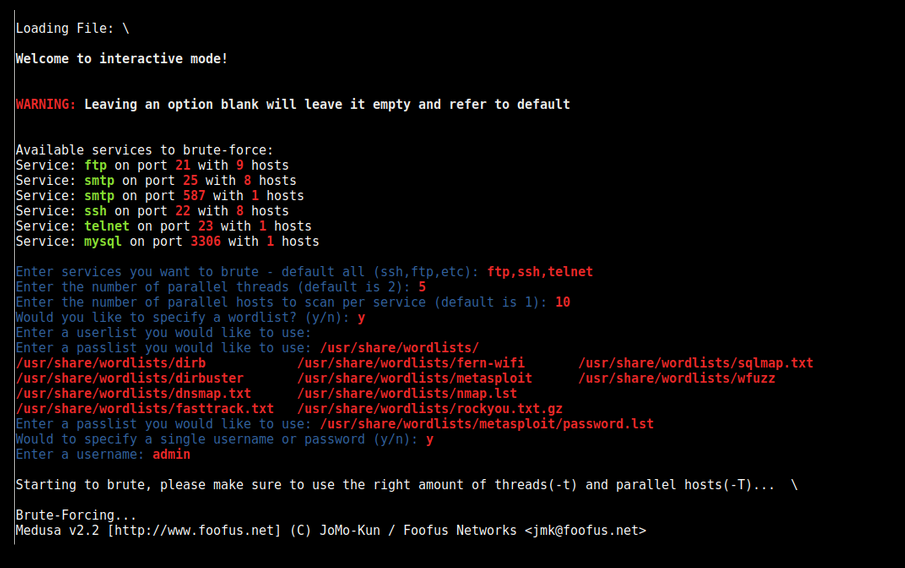
Une fois que vous commencez à faire du scan de ports sur votre cible, il y a un certain nombre de ports qui vont devenir intéressants pour vous. Vous allez avoir des protocoles d'administration à distance comme FTP ou SSH, et bien que votre bounty soit plus focalisé sur le web, ces choses sont toujours associées aux serveurs et s'ils sont vulnérables soit au brute force d'identifiants soit à un overflow dans le logiciel, cela peut être intéressant.
BruteSpray est un outil qui va prendre notre sortie de scan précédente (format nmap avec la sortie du scanning de version), et l'analyser, et quand BruteSpray rencontrera un de ces protocoles d'administration à distance (comme FTP ou SSH) il utilisera une petite wordlist pour essayer de brute forcer ces hôtes (il utilise Medusa), avec des mots de passe courants, des mots de passe par défaut ou une connexion anonyme.

Voici à quoi ressemble BruteSpray :
Identification visuelle avec EyeWitness
Nous avons une tonne de domaines de premier niveau et de sous-domaines que nous avons scrappés ou brute forcés sur Internet. Mais le problème est qu'ils pourraient ne plus être actifs, et nous avons aussi des références à eux dans un format qui ne nous dit pas quel protocole ils utilisent (HTTP ou HTTPS).
Nous allons donc utiliser un outil appelé EyeWitness, il va prendre une liste de domaines sans protocole et il va visiter chacun avec un navigateur headless et prendre une capture d'écran de ce qu'il voit, puis les déverser dans un rapport. Cela nous permet de savoir quels domaines redirigent réellement vers la même application, quels domaines sont intéressants à pirater en premier, quels domaines ne répondent pas, etc... en regardant les captures d'écran prises par l'outil. L'outil va aussi essayer les deux protocoles sur chaque domaine, donc nous saurons quels protocoles sont utilisés par chaque domaine.
Vous pouvez trouver l'outil EyeWitness ici : https://github.com/FortyNorthSecurity/EyeWitness.
Voici la commande pour exécuter EyeWitness :
python EyeWitness.py --prepend-https -f ../domain/tesla.com.lst --all-protocols --headless
Note : si vous rencontrez une page d'erreur 401/403, une authentification basique, ou un domaine qui semble intéressant mais qui est d'une certaine manière verrouillé, il peut être utile de regarder les entrées sur https://archive.org/web/. Parfois vous pouvez trouver des clés API ou une structure d'URL que vous pouvez utiliser pour naviguer de force vers du contenu non protégé toujours présent. Ces outils peuvent aussi être utilisés : https://github.com/tomnomnom/waybackurls et https://github.com/mhmdiaa/waybackunifier.
Restez organisé
Pendant votre chasse aux bugs, vous allez collecter beaucoup d'informations, des sorties de différents outils, des listes de domaines et sous-domaines, des sorties de scans de ports... et c'est encore plus vrai pour les bounties à large scope. Il est donc très important de rester organisé, de prendre des notes claires de toutes les informations collectées, et de toutes les étapes réalisées.
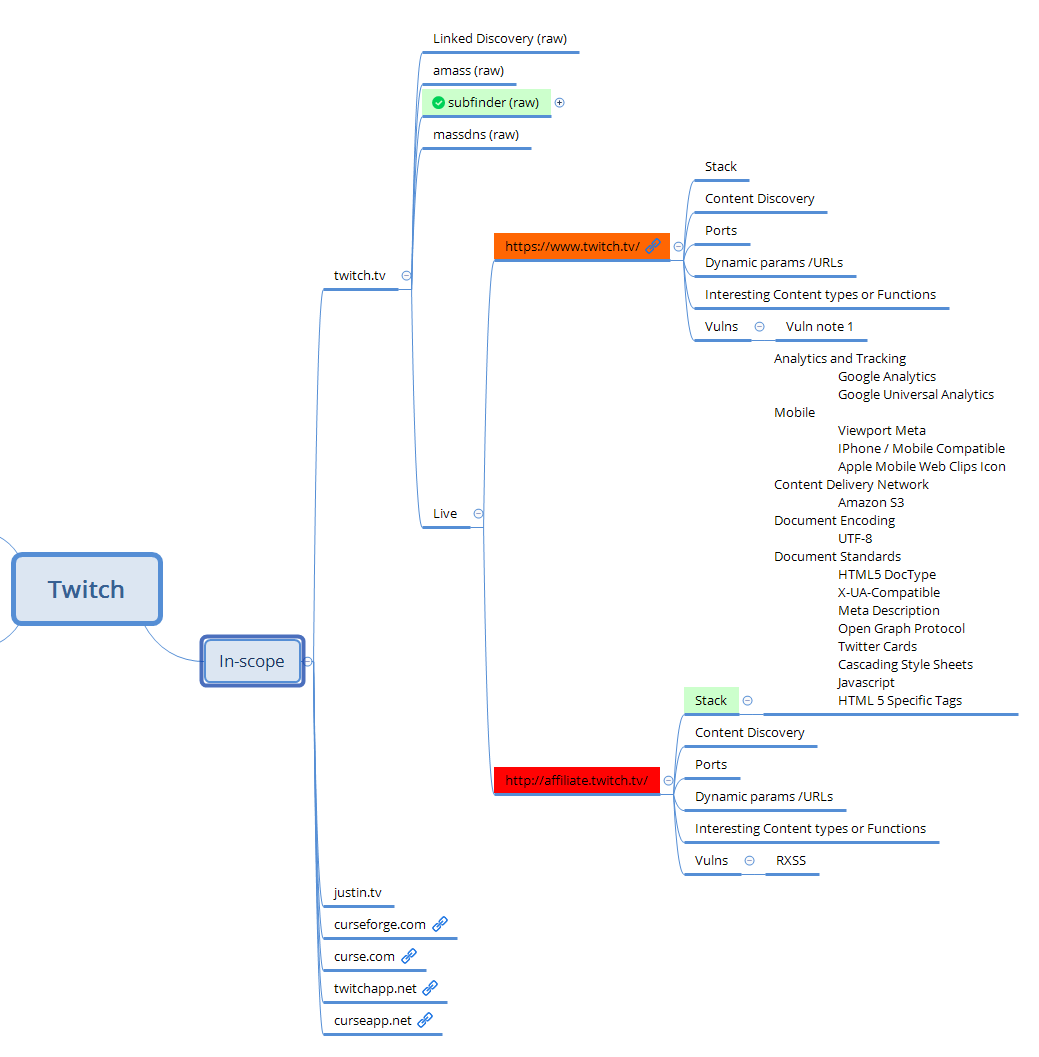
Organisation avec Xmind
Pour suivre votre progression, il peut être utile d'utiliser un logiciel de mind mapping comme Xmin Organization. Avec cet outil, il est facile de suivre tous vos outils utilisés et de suivre la progression sur un bounty donné.
Identification de plateforme et recherche de CVE
Maintenant que vous avez une liste de sites sur lesquels vous avez fait du scan de ports, il est temps de se concentrer sur les sites individuels. Voici une liste de quelques outils qui peuvent être utiles.
Retire.js
Retire.js est un outil puissant qui permet de scanner une application web ou une application node pour l'utilisation de bibliothèques JavaScript vulnérables et/ou de modules node. C'est important de vérifier les bibliothèques des sites, car "Utilisation de composants avec des vulnérabilités connues" fait maintenant partie du OWASP Top 10. Donc Retire.js vous dira si les bibliothèques utilisées par le site sont obsolètes, et s'il y a des vulnérabilités associées à cette version.
Vous pouvez trouver Retire.js ici : https://retirejs.github.io/retire.js/.
Burp Vulners Scanner
Burp-vulners-scanner est un plugin Burp basé sur https://vulners.com/. Chaque fois qu'il voit un header de serveur qui indique le numéro de version du serveur ou qu'il trouve un fichier readme qui contient un numéro de version, il vous alertera et vous indiquera tous les CVEs associés à ce numéro de version. Il existe plusieurs façons d'essayer de trouver le numéro de version du framework ou du serveur web. Donc ce scanner est très utile pour les logiciels serveur, les installations wordpress, essentiellement tout ce dont il peut extraire une version.
Vous pouvez trouver le Burp-vulners-scanner ici : https://github.com/vulnersCom/burp-vulners-scanner.
Parsing du JavaScript
- Zap Ajax Spider : si vous passez de Burp à Zap, il y a le plugin Ajax Spider, il peut être très utile pour parser le javascript des sites web.
- LinkFinder : c'est un script python écrit pour découvrir les endpoints et leurs paramètres dans les fichiers JavaScript. Il est donc vraiment utile pour trouver des URLs dans les fichiers javascript.
- JS Parser : un autre script python utilisant Tornado et JSBeautifier pour parser les URLs relatives depuis les fichiers JavaScript.
Découverte de contenu
La découverte de contenu est l'idée de brute forcer des chemins d'URL.
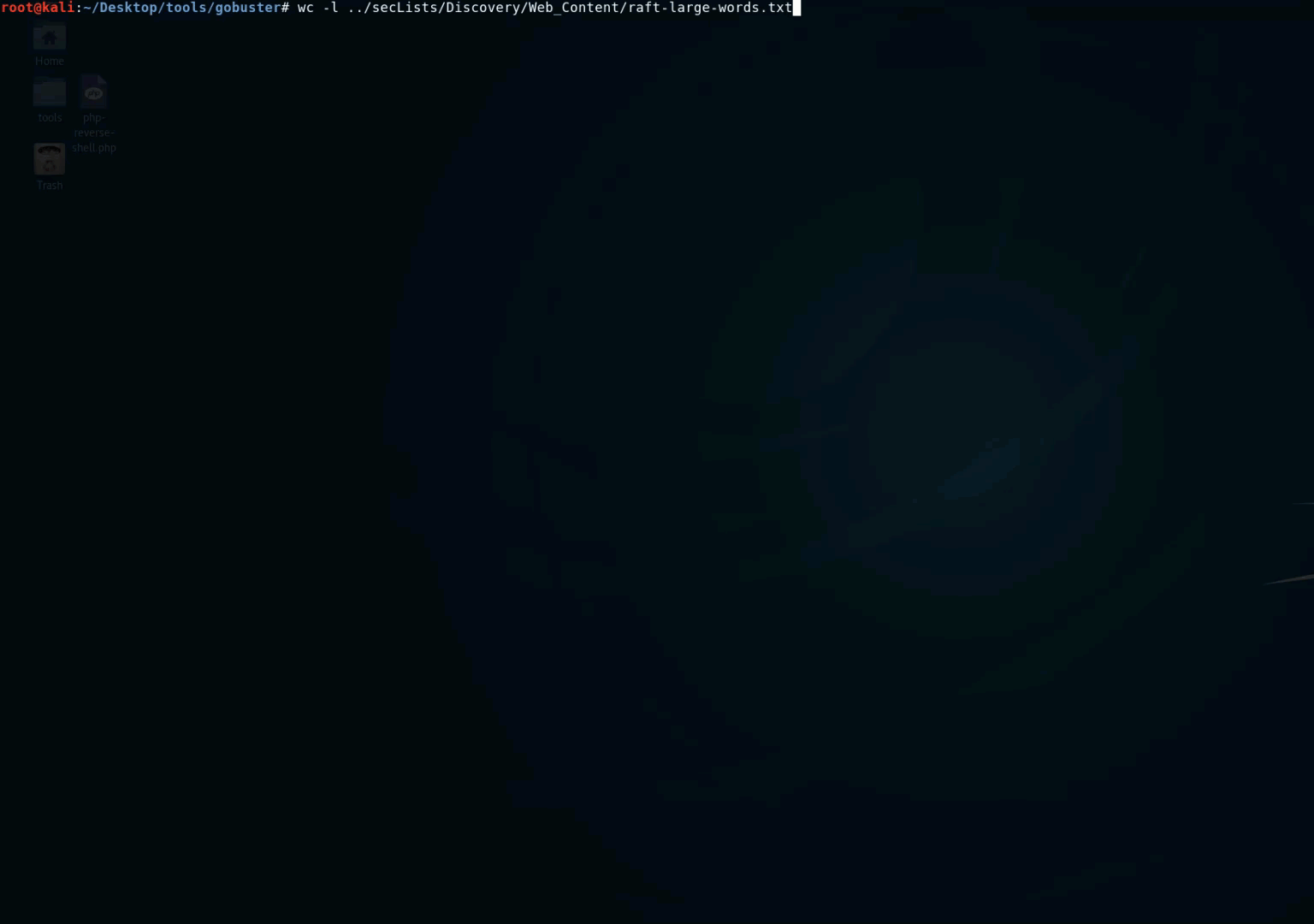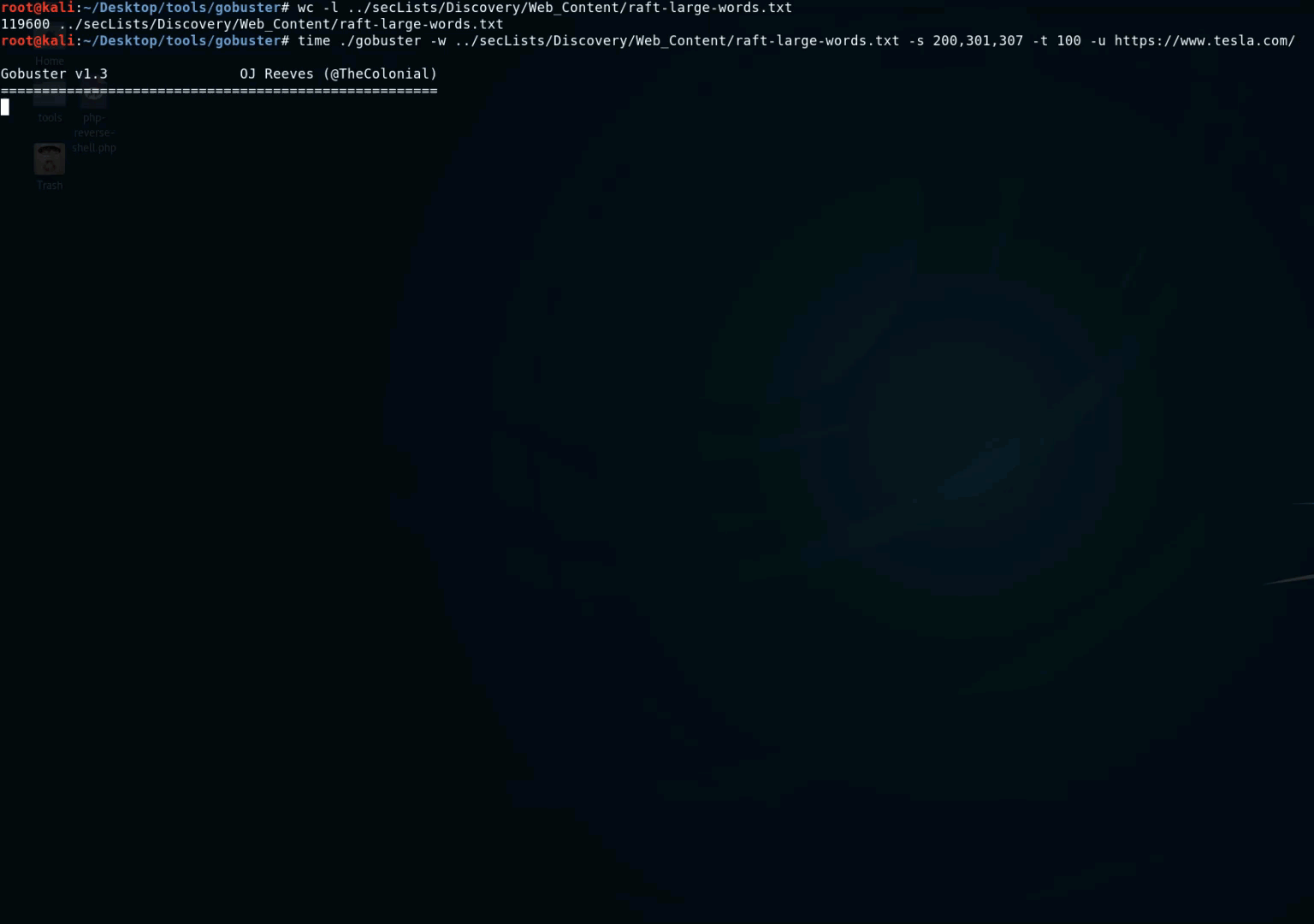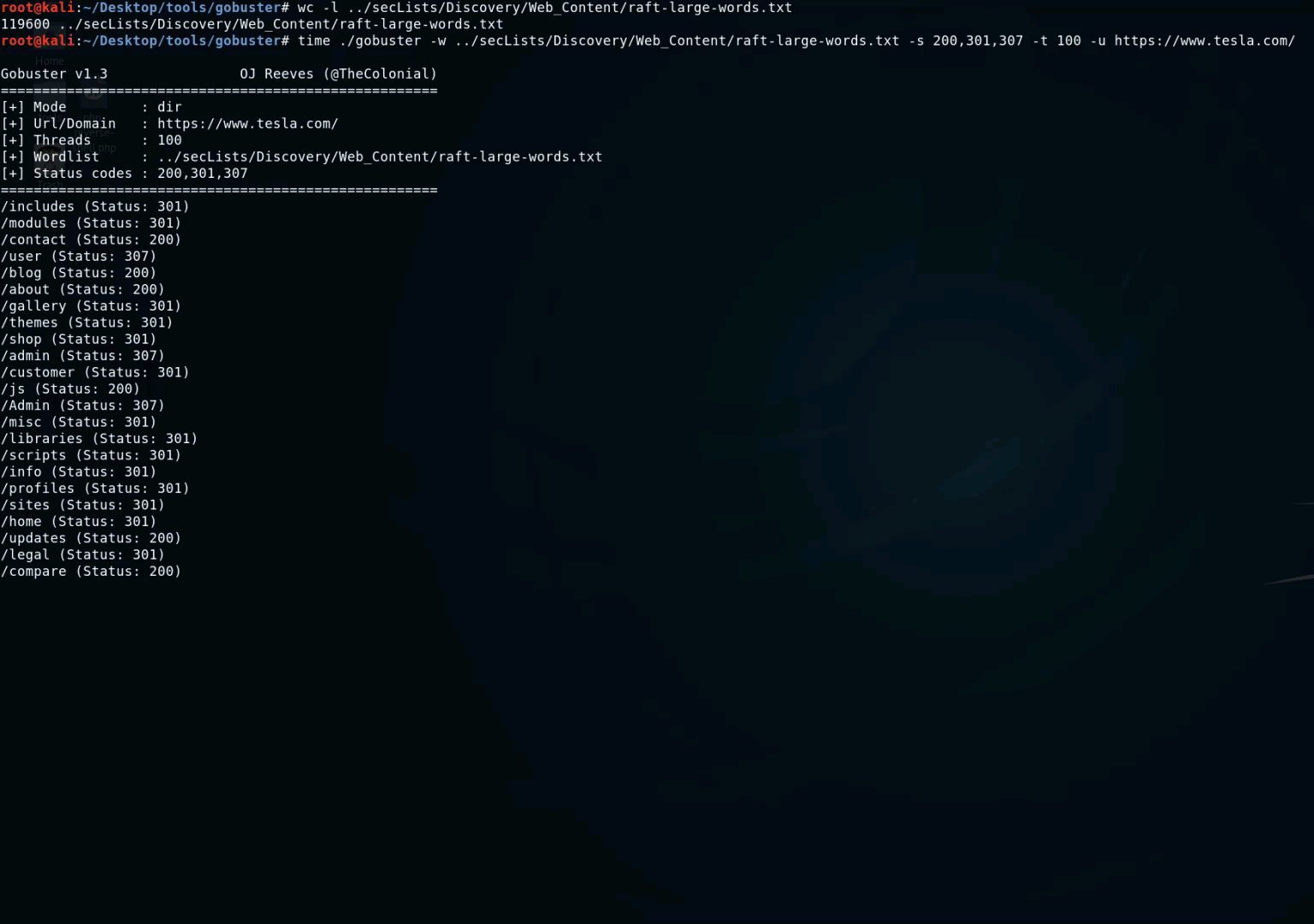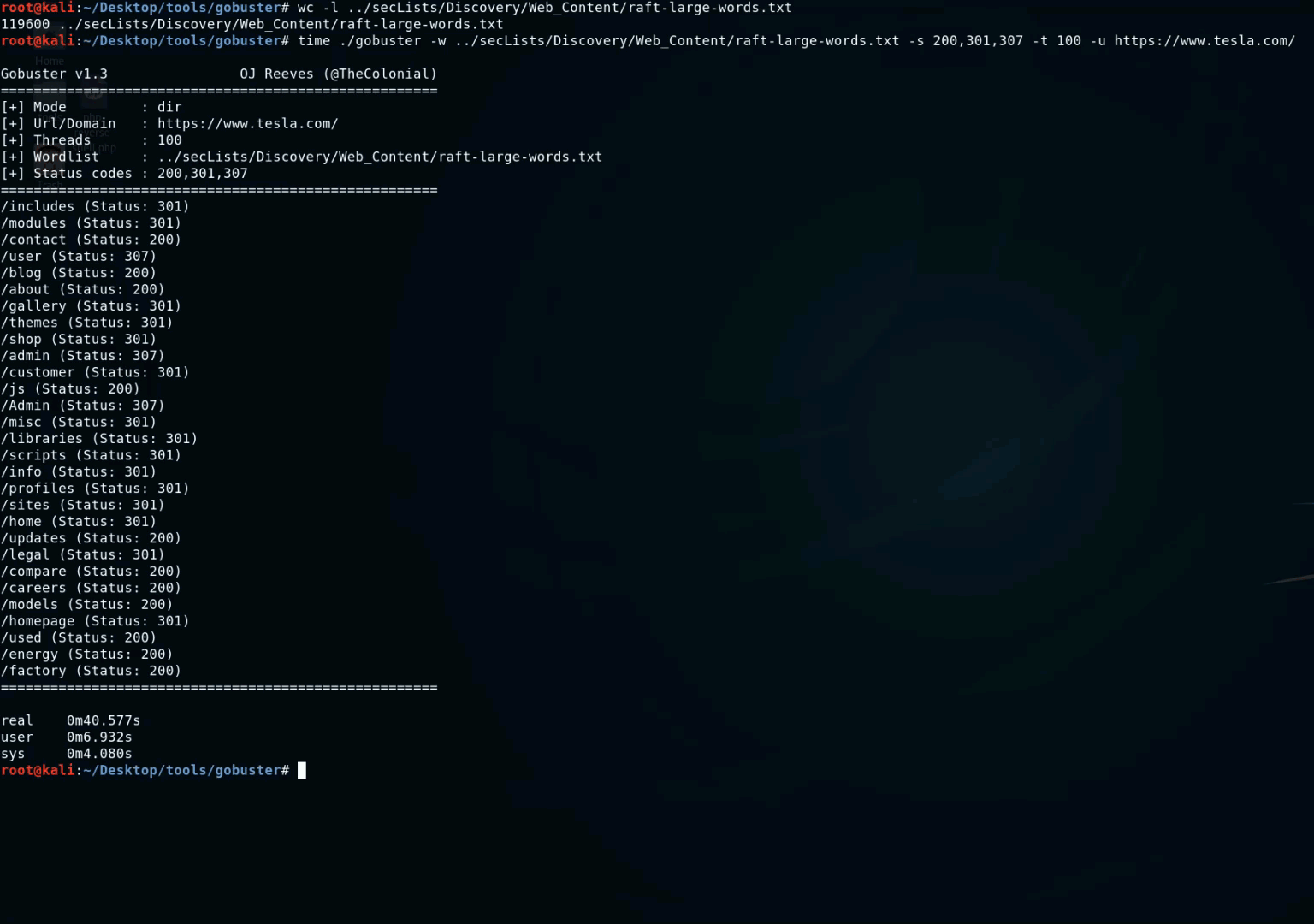
- GoBuster : c'est un outil utilisé pour brute forcer les URIs (répertoires et fichiers) dans les sites web, les sous-domaines DNS, les noms d'hôtes virtuels sur les serveurs web cibles. Il est écrit en Go et il est vraiment rapide. Vous pouvez utiliser cette wordlist avec GoBuster : https://gist.github.com/jhaddix/b80ea67d85c13206125806f0828f4d10.
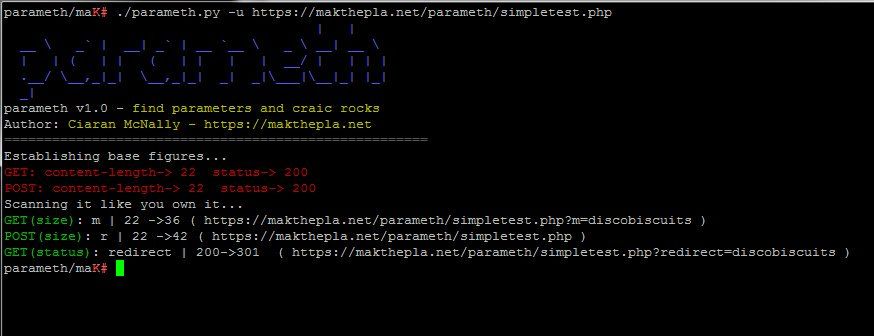
- Parameth : quand vous avez un script et que vous ne savez pas quels paramètres il prend, Parameth est l'outil à utiliser dans cette situation.
XSS
S3Scanner
Résumé
Voici l'ensemble de la méthodologie de reconnaissance :
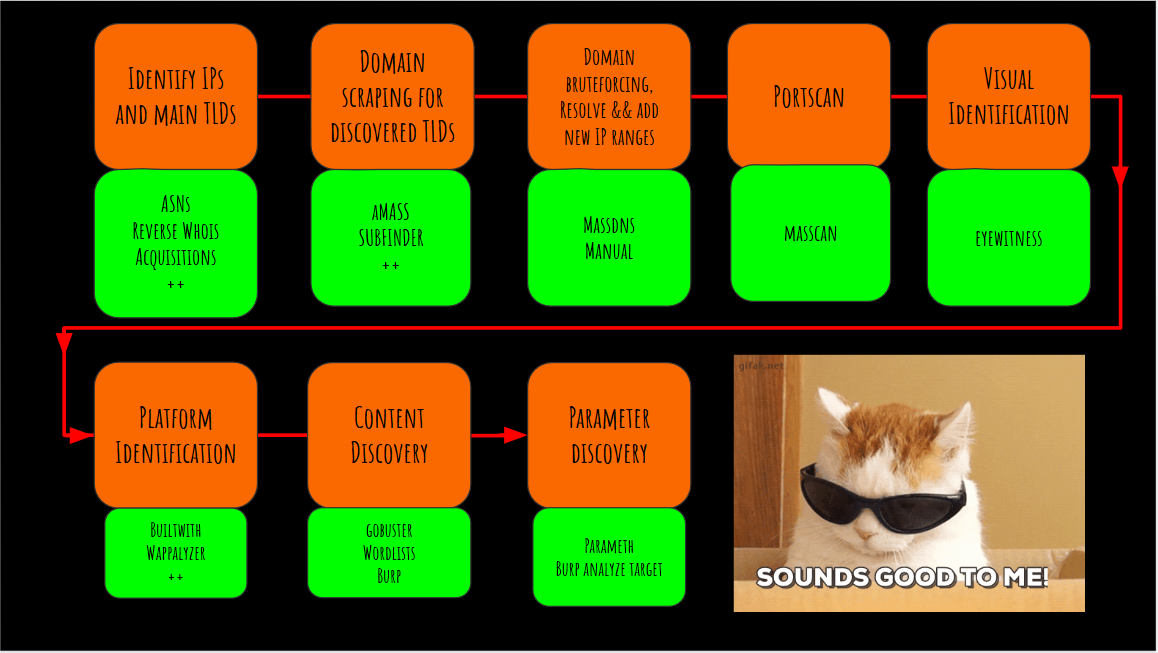
Tous les crédits vont à Jason Haddix, sa présentation est vraiment utile pour comprendre comment réaliser un programme de bug bounty. Je conseille à tout le monde de regarder ses vidéos pour en apprendre plus sur ce sujet.
C'est la voie pour devenir un Bug Bounty Hunter.